
Looking to run large language models (LLMs) directly on your desktop? Here’s a guide on how to set up Docker Model Runner and access powerful LLMs locally.
Docker Model Runner is a newly introduced feature within Docker Desktop designed to simplify running and testing AI models on your local machine. It addresses common issues developers face when working with generative AI, such as complicated environment setups, inconsistent model management, and scattered tooling.
Instead of requiring every AI workload to run inside a container, Docker Model Runner embeds a native inference engine directly in Docker Desktop. This engine, currently based on llama.cpp, runs as a native process on your host, allowing efficient model loading and better utilization of hardware, including GPU acceleration on Apple silicon Macs. Running models natively avoids the usual performance overhead seen when running AI inside containers or virtual machines, resulting in faster inference times and smoother development.
Prerequisites for Docker Model Runner
To use Docker Model Runner, make sure you have Docker Desktop version 4.41 or newer installed, since the feature is integrated into recent releases. If you plan to use Docker Compose with multi-container setups, ensure Docker Compose is at least version 2.35.
Hardware requirements are important: on Mac, Model Runner works only with Apple silicon chips like M1 or M2. For Windows users, an NVIDIA GPU is needed to benefit from hardware acceleration. Currently, Linux systems and Intel-based Macs aren’t supported.
Enabling Model Runner
With the latest Docker Desktop installed, enable Model Runner through the Dashboard settings.
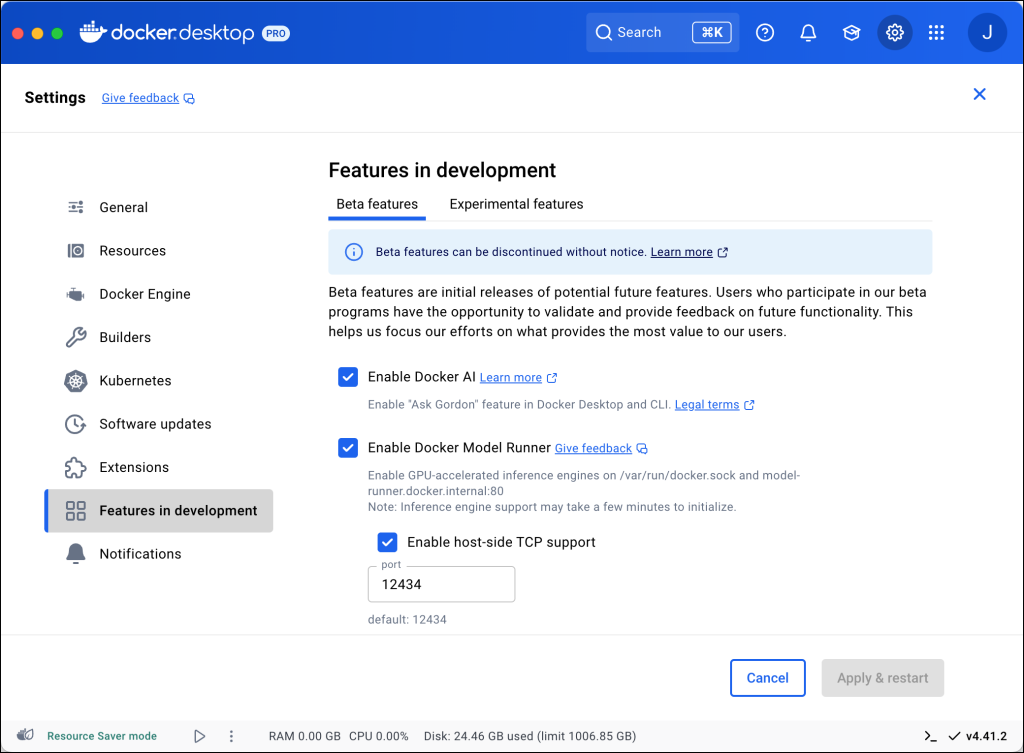
Alternatively, from the terminal, run:
docker desktop enable model-runner --tcp 12434
This will start the llama.cpp inference engine on macOS. Verify it’s running by typing:
docker model status
Once enabled, you can manage models using commands similar to Docker images. For example, list downloaded models with:
docker model list
Pulling and Running the Gemma LLM
Docker provides a registry for generative AI models, hosted at hub.docker.com/u/ai, where models are stored in OCI format, similar to container images.
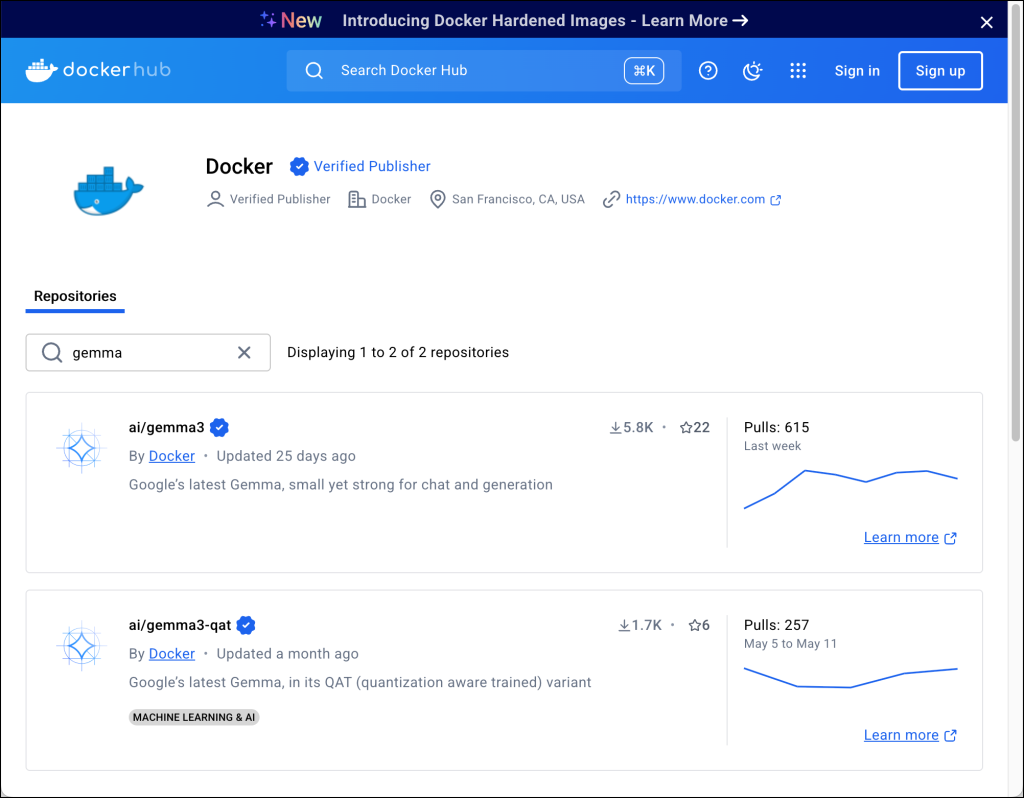
To download the Gemma3 model, run:
docker model pull ai/gemma3
Confirm the model is available with:
docker model list
Access the model via an OpenAI-compatible API by sending a cURL request like this:
curl http://localhost:12434/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/gemma3",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who was the captain of the Indian cricket team during the 1983 World Cup?"}
]
}'
Pulling and Running Embedding Models From Hugging Face
Docker Model Runner can also pull models from Hugging Face, as long as they are compatible with llama.cpp. For example, to get the mxbai-embed-large-v1 embedding model:
docker model pull hf.co/mixedbread-ai/mxbai-embed-large-v1
This GGUF-formatted model is optimized for CPU use and works seamlessly with llama.cpp. Test the embedding model using:
curl http://localhost:12434/engines/llama.cpp/v1/embeddings \
-H "Content-Type: application/json" \
-d '{
"model": "hf.co/mixedbread-ai/mxbai-embed-large-v1",
"input": "Embeddings made easy"
}'
Models you download appear in the Docker Desktop dashboard for easy management.
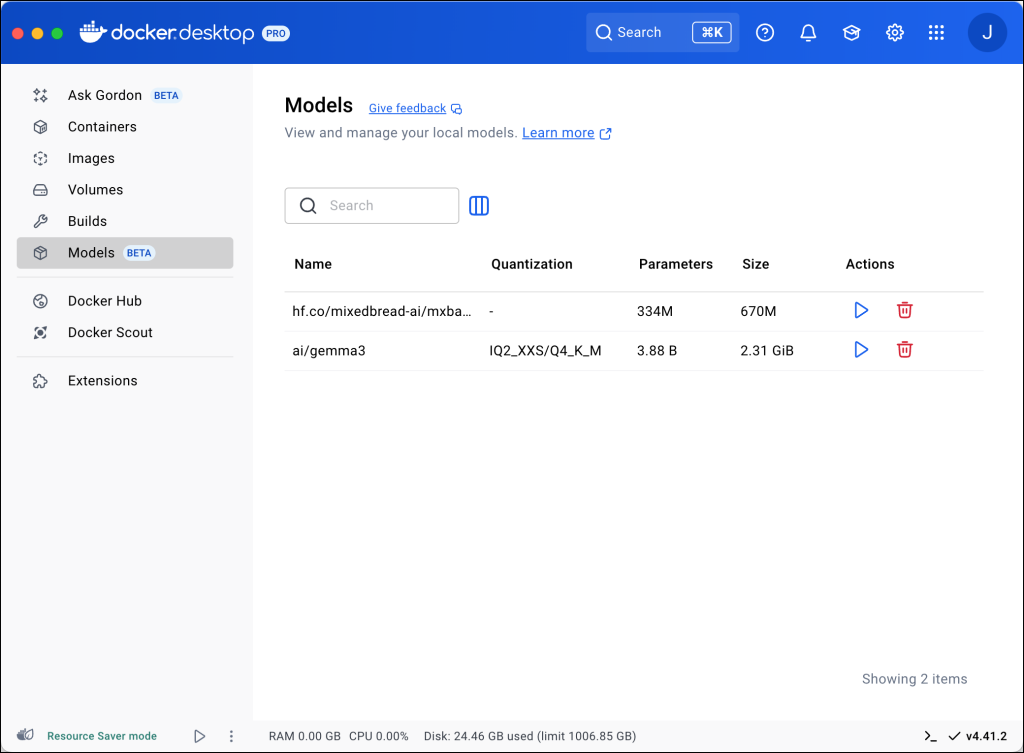
With both an embedding model and a large language model running locally, you can build Retrieval-Augmented Generation (RAG) and agentic applications directly on your development setup, without relying on cloud inference services.
Docker Model Runner represents a major step forward for local AI development by combining speed, simplicity, and deep integration with Docker’s ecosystem. Developers can effortlessly pull, run, and maintain AI models on their own machines, sidestepping complicated infrastructure or container overhead. Thanks to its native inference engine and support for GPU acceleration—especially on Apple silicon—Model Runner delivers fast, efficient performance. Distributing models as OCI artifacts standardizes how they’re packaged and versioned, fitting neatly into existing Docker workflows. Plus, using OpenAI-compatible APIs ensures easy integration with current applications and tools.


